Active Vision and Multi-agent Reinforcement Learning
End-to-end Active Object Tracking and Its Real-world Deployment
We study active object tracking, where a tracker takes as input the visual observation and produces the control signal to actively move the camera. we propose an end-to-end solution via deep reinforcement learning, where a ConvNet-LSTM function approximator is adopted for the direct frame-to-action prediction. We also introduce an environment augmentation technique and a customized reward function, which are crucial for successful training a generalizable tracker. Furthermore, we deliver a successful deployment of the proposed active tracking method in a real-world robot, which verifies its practical values.

Training with advanced environment augmentation in UE4

The real-world deployment
An Asymmetric Dueling mechanism for learning Visual Active Tracking
We propose a novel adversarial reinforcement learning (RL) method which adopts an Asymmetric Dueling mechanism for learning Visual Active Tracking(VAT), referred to as AD-VAT. In the mechanism, the tracker and target, viewed as two learnable agents, are opponents and can mutually enhance each other during the dueling/competition: i.e., the tracker intends to lockup the target, while the target tries to escape from the tracker. The proposed method leads to faster convergence in training and yields more robust tracking behaviors in different unseen scenarios.
Collaborative Deep Reinforcement Learning for Joint Object Search
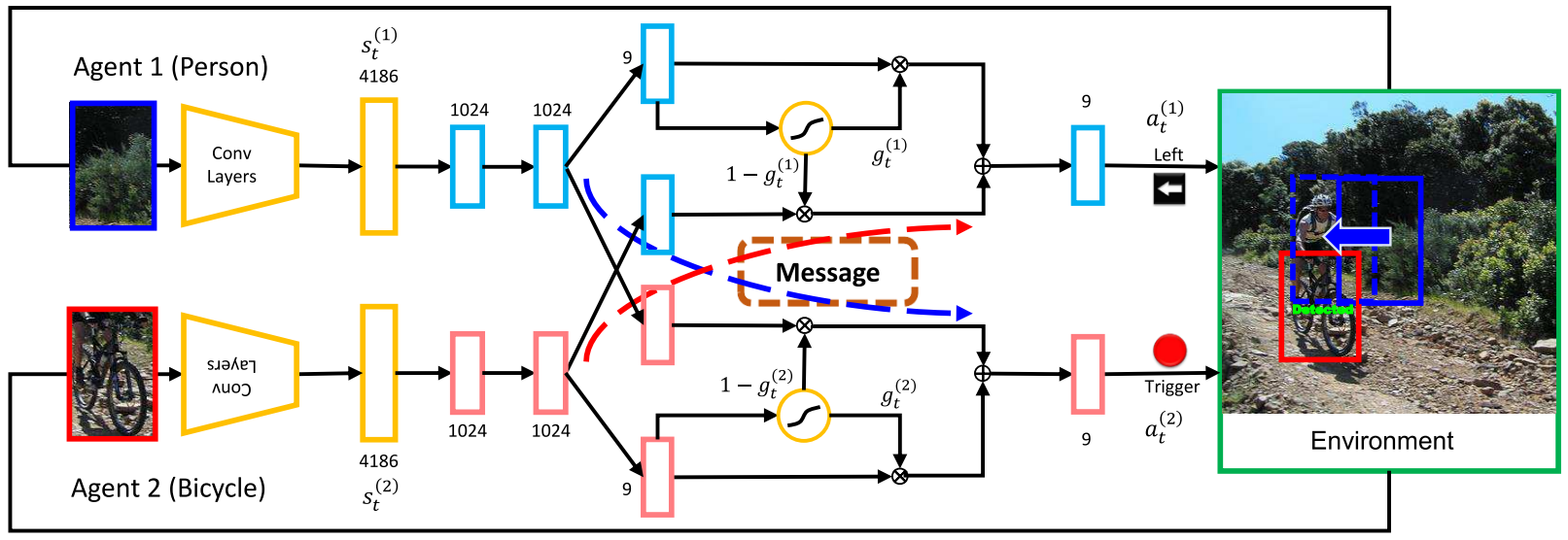
We examine the problem of joint top-down active search of multiple objects under interaction, e.g., person riding a bicycle, cups held by the table, etc.. Such objects under interaction often can provide contextual cues to each other to facilitate more efficient search. By treating each detector as an agent, we present the first collaborative multi-agent deep reinforcement learning algorithm to learn the optimal policy for joint active object localization, which effectively exploits such beneficial contextual information. We learn inter-agent communication through cross connections with gates between the Q-networks, which is facilitated by a novel multi-agent deep Q-learning algorithm with joint exploitation sampling. We verify our proposed method on multiple object detection benchmarks. Not only does our model help to improve the performance of state-of-the-art active localization models, it also reveals interesting co-detection patterns that are intuitively interpretable.
Effective Master-Slave Communication for Multi-Agent Reinforcement Learning
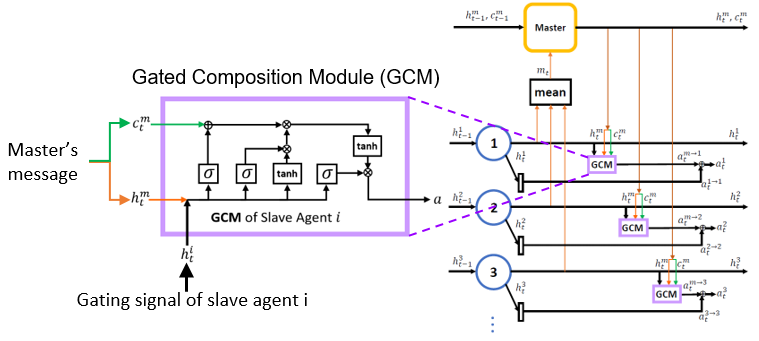
Communication becomes a bottleneck when a multi-agent system (MAS) scales. This is particularly true when a MAS is deployed to autonomous learning (e.g. reinforcement learning), where massive interactive communication is required. We argue that the effectiveness of communication is a key factor to determine the intelligence level of a multi-agent learning system. In this regard, we propose to adapt the classical hierarchical master-slave architecture to facilitate efficient multi-agent communication during the interactive reinforcement learning (RL) process implemented on a deep neural network. The master agent aggregates messages uploaded from the slaves and generates unique message to each slave according to the aggregated information and the states of the slave. Each slave incorporates both the instructive messages from the master and its own to take actions to fulfill the goal. In this way, the joint action-state space of the agents grows only linearly instead of geometrically with the number of agents compared to the peer-to-peer architecture.
Exploiting Semantic Information in Visual Tasks
Robust 3D Human Pose Estimation from Single Images or Video Sequences
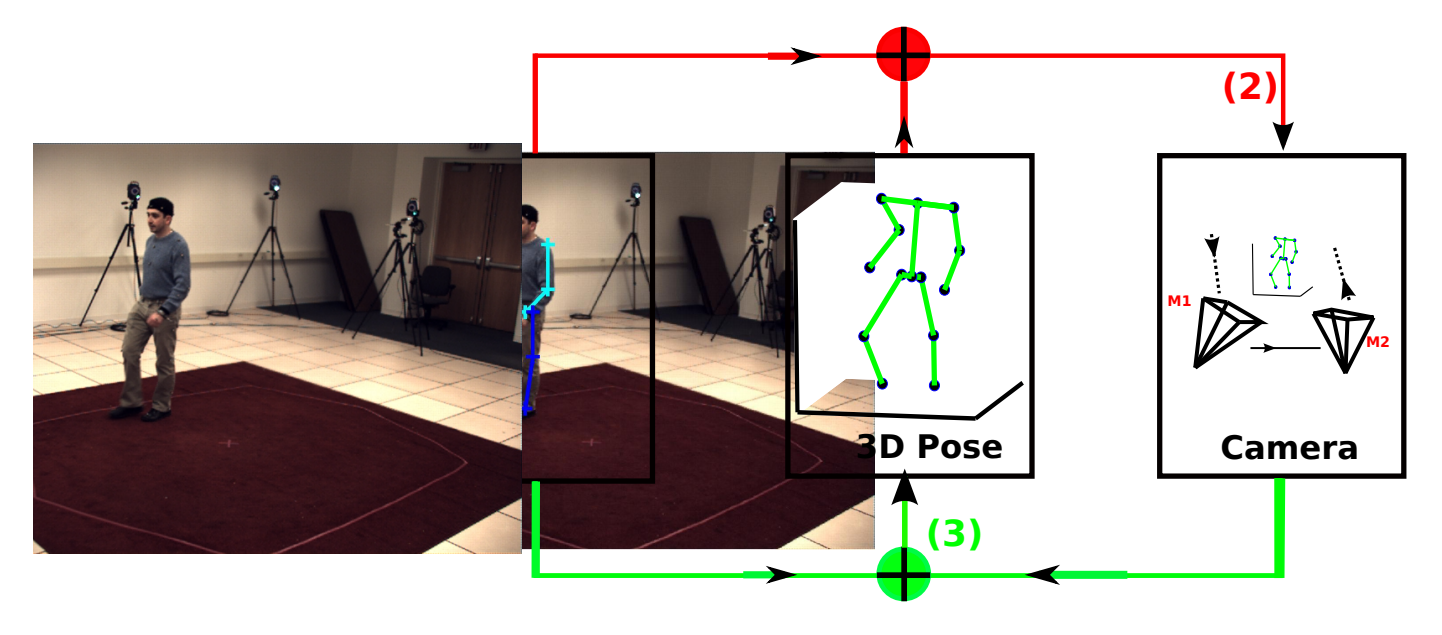
We propose a method for estimating 3D human poses from single images or video sequences. The task is challenging because: (a) many 3D poses can have similar 2D pose projections which makes the lifting ambiguous, and (b) current 2D joint detectors are not accurate which can cause big errors in 3D estimates. We represent 3D poses by a sparse combination of bases which encode structural pose priors to reduce the lifting ambiguity. This prior is strengthened by adding limb length constraints. We estimate the 3D pose by minimizing an L1-norm measurement error between the 2D pose and the 3D pose because it is less sensitive to inaccurate 2D poses. We modify our algorithm to output K 3D pose candidates for an image, and for videos, we impose a temporal smoothness constraint to select the best sequence of 3D poses from the candidates. We demonstrate good results on 3D pose estimation from static images and improved performance by selecting the best 3D pose from the K proposals. Our results on video sequences also show improvements (over static images) of roughly 15%.
Video Object Segmentation by Learning Location-Sensitive Embeddings
We address the problem of video object segmentation which outputs the masks of a target object throughout a video given only a bounding box in the first frame. There are two main challenges to this task. First, the background may contain similar objects as the target. Second, the appearance of the target object may change drastically over time. To tackle these challenges, we propose an end-to-end training network which accomplishes foreground predictions by leveraging the location-sensitive embeddings which are capable to distinguish the pixels of similar objects. To deal with appearance changes, for a test video, we propose a robust model adaptation method which pre-scans the whole video, generates pseudo foreground/background labels and retrains the model based on the labels. Our method outperforms the state-of-the-art methods on the DAVIS and the SegTrack v2 datasets.
No-Reference Image Quality Assessment: An Attention-Driven Approach
We propose a novel no-reference image quality assessment method. The dynamic attentional mechanism is considered for the first time in the proposed method. We assume that the attentional regions include essential information for assessing image quality. We adopt reinforcement learning to learn the attentional policy. The method can provide a robust and efficient indicator of perceptual quality. In the same time, the multi-task learning mechanism is utilized to improve the representation learning and generalization ability of our model.
Real-Time Video Anomaly Detection via Binary Quantized Feature and Spatial-Temporal Context Modelling
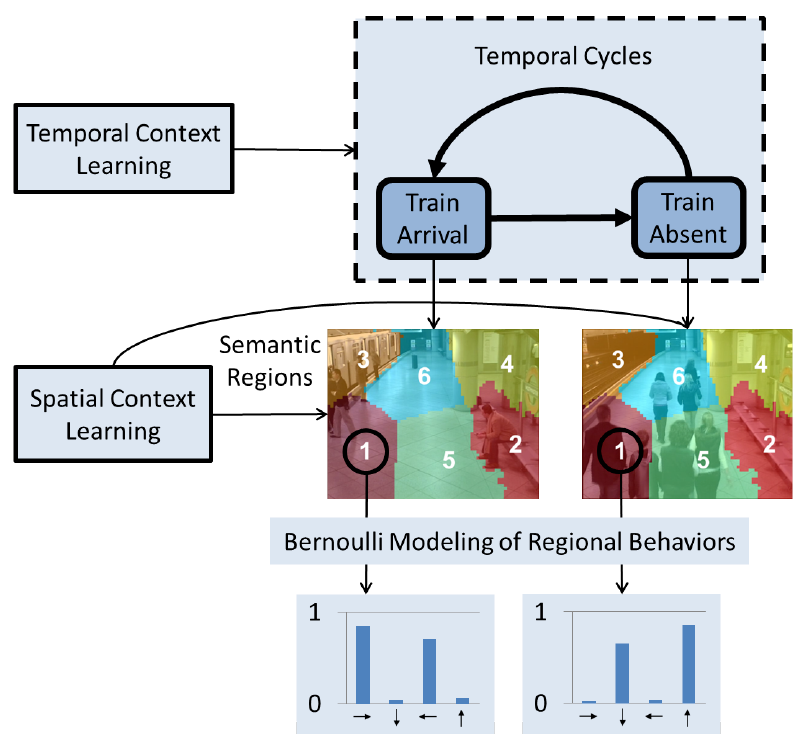
Modeling complex crowd behaviour for tasks such as rare event detection has received increasing interest. However, existing methods are limited because (1) they are sensitive to noise often resulting in a large number of false alarms; and (2) they rely on elaborate models leading to high computational cost thus unsuitable for processing a large number of video inputs in real-time. In this paper, we overcome these limitations by introducing a novel complex behaviour modeling framework, which consists of a Binarized Cumulative Directional (BCD) feature as representation, novel spatial and temporal context modeling via an iterative correlation maximization, and a set of behaviour models, each being a simple Bernoulli distribution. Despite its simplicity, our experiments on three benchmark datasets show that it significantly outperforms the state-of-the-art for both temporal video segmentation and rare event detection. Importantly, it is extremely efficient — reaches 90Hz on a normal PC platform using MATLAB.
Face Detection with End-to-End Integration of a ConvNet and a 3D Model
Face detection has been used as a core module in a wide spectrum of applications. However, it remains a challenging problem in computer vision due to the large appearance variations caused by nuisance variabilities including viewpoints, occlusion, facial expression, etc. This paper presents a method for face detection in the wild, which integrates a ConvNet and a 3D mean face model in an end-to-end multi-task discriminative learning framework. The ConvNet consists of two components: (i) The face proposal component computes face bounding box proposals via estimating facial key-points and the 3D transformation (rotation and translation) parameters for each predicted key-point w.r.t. the 3D mean face model. (ii) The face verification component computes detection results by pruning and refining proposals based on facial key-points based configuration pooling.
Medical Visual Information Processing
Joint Learning for Pulmonary Nodule Segmentation, Attributes and Malignant Prediction
Existing methods cannot tell how the CNN works in terms of predicting the malignancy of the given nodule. We propose an interpretable and multi-task learning CNN. It is able to not only accurately predict the malignancy of lung nodules, but also provide semantic high-level attributes as well as the areas of detected nodules. Moreover, the combination of nodule segmentation, attributes and malignancy prediction is helpful to improve the performance of each single task.
FDR-HS: an empirical bayesian identification of heterogenous features in neuroimage analysis
To address the problem of heterogeneity between lesion features and procedural biaswe propose a “two-groups” Empirical-Bayes method called “FDR-HS” (FalseDiscovery-Rate Heterogenous Smoothing). Such method is able to not only avoid multicollinearity, but also exploit the heterogenous spatial patterns of features. In addition, it enjoys the simplicity in implementation by introducing hidden variables, which turns the problem into a convex optimization scheme and can be solved efficiently by the expectation maximum (EM) algorithm. Empirical experiments have been evaluated on the Alzheimer’s Disease Neuroimage Initiative (ADNI) database. The advantage of the proposed model is verified by improved interpretability and prediction power using selected features by FDR-HS.
Cascaded Generative and Discriminative Learning for Microcalcification Detection in Breast Mammograms
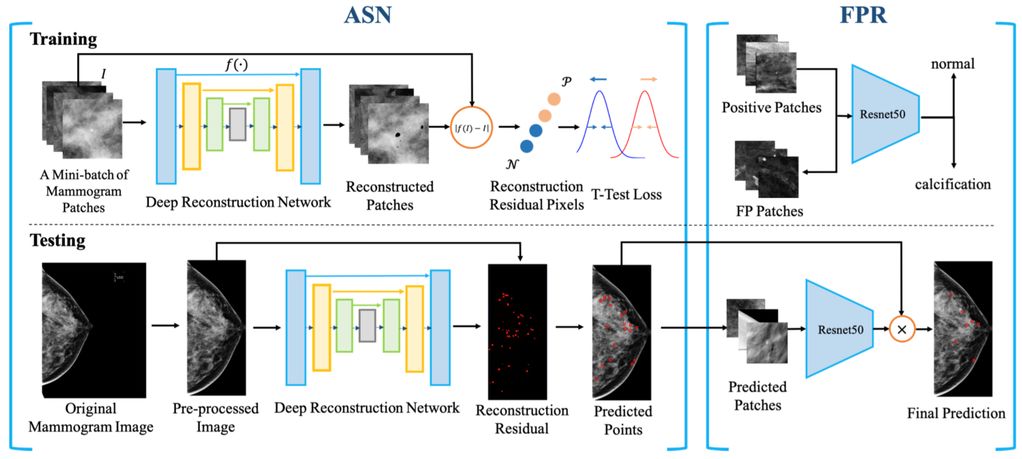
Accurate microcalcification (mC) detection is of great importance due to its high proportion in early breast cancers. Most of the previous mC detection methods belong to discriminative models, where classifiers are exploited to distinguish mCs from other backgrounds. However, it is still challenging for these methods to tell the mCs from amounts of normal tissues because they are too tiny (at most 14 pixels). Generative methods can precisely model the normal tissues and regard the abnormal ones as outliers, while they fail to further distinguish the mCs from other anomalies, i.e. vessel calcifications. In this paper, we propose a hybrid approach by taking advantages of both generative and discriminative models. Firstly, a generative model named Anomaly Separation Network (ASN) is used to generate candidate mCs. ASN contains two major components. A deep convolutional encoder-decoder network is built to learn the image reconstruction mapping and a t-test loss function is designed to separate the distributions of the reconstruction residuals of mCs from normal tissues. Secondly, a discriminative model is cascaded to tell the mCs from the false positives. Finally, to verify the effectiveness of our method, we conduct experiments on both public and in-house datasets, which demonstrates that our approach outperforms previous state-of-the-art methods.
Efficient Generalized Fused Lasso and its Applications
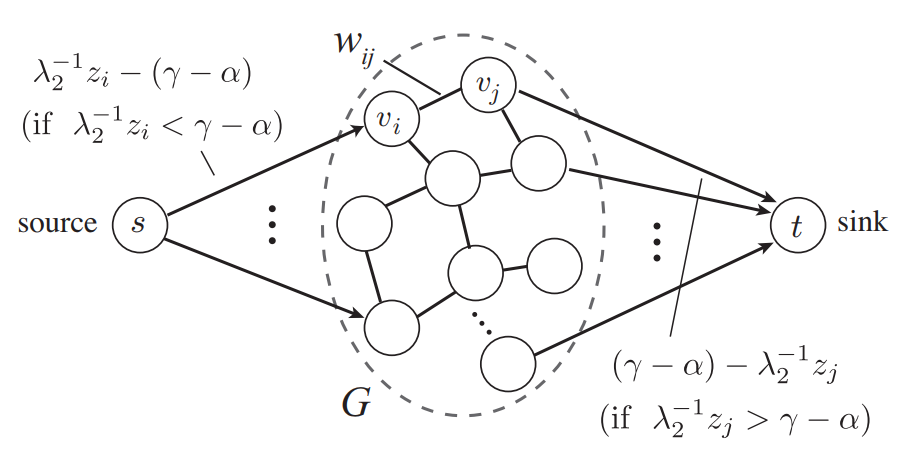
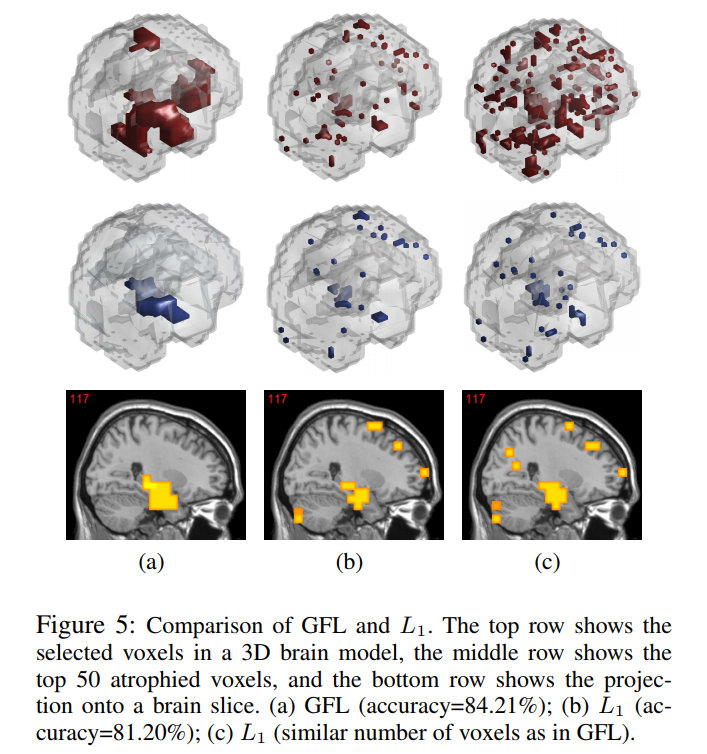
Generalized fused lasso (GFL) penalizes variables with l1 norms based both on the variables and their pairwise differences. GFL is useful when applied to data where prior information is expressed using a graph over the variables. However, the existing GFL algorithms incur high computational costs and do not scale to high-dimensional problems. In this study, we propose a fast and scalable algorithm for GFL. Based on the fact that fusion penalty is the Lovász extension of a cut function, we show that the key building block of the optimization is equivalent to recursively solving graph-cut problems. Thus, we use a parametric flow algorithm to solve GFL in an efficient manner. Runtime comparisons demonstrate a significant speedup compared to existing GFL algorithms. Moreover, the proposed optimization framework is very general; by designing different cut functions, we also discuss the extension of GFL to directed graphs. Exploiting the scalability of the proposed algorithm, we demonstrate the applications of our algorithm to the diagnosis of Alzheimer’s disease (AD) and video background subtraction (BS). In the AD problem, we formulated the diagnosis of AD as a GFL regularized classification. Our experimental evaluations demonstrated that the diagnosis performance was promising. We observed that the selected critical voxels were well structured, i.e., connected, consistent according to cross validation, and in agreement with prior pathological knowledge. In the BS problem, GFL naturally models arbitrary foregrounds without predefined grouping of the pixels. Even by applying simple background models, e.g., a sparse linear combination of former frames, we achieved state-of-the-art performance on several public datasets.
GSplit LBI: Taming the Procedural Bias in Neuroimaging for Disease Prediction
In voxel-based neuroimage analysis, we observe that there exist another type of features can help classification of disease, in addition to lesion features. Since such features are introduced during the preprocessing steps, we call them “Procedural Bias”.In this paper, a novel dual-task algorithm namely GSplit LBI is proposed to capture such features, in order to improve classification accuracy and interpretability. Our method can achieved state-of-the-art result on ADNI database, using sMRI modality.