Video Coding Standard
Our video coding lab has been committed to the research of video coding standard technology for many years. We focus on proposing techniques in international standards from H.264, HEVC to the latest VVC, and leading to making domestic standards from AVS, AVS2, to the latest AVS3. We have put forward a number of core technologies, and a large of technical proposals have been adopted in these standards.
1. High Efficiency Video Coding (HEVC)
In April 2010, the ITU-T Video Coding Expert Group (VCEG) and ISO/IEC Moving Picture Experts Group (MPEG) formed the Joint Collaborative Team on Video Coding (JCT-VC) to develop the new coding standard, which is known as High Efficiency Video Coding (HEVC) or H.265, formally published in 2013. HEVC can achieve about 50% bit-rate saving compared to H.264/AVC.
We have investigated many techniques based on HEVC.
Adaptive Progressive Motion Vector Resolution Selection
It is widely acknowledged that the resolution of motion vector has a significant impact on coding performance. Generally speaking, on one hand, higher MV resolution implies that more potential sub-pel positions will be searched during the motion estimation (ME), leading to lower prediction distortion. On the other hand, the rate used for coding the motion vector constraints the MV resolution as MVs with higher resolution desire more coding bits for lossless representation. We proposed an adaptive MV resolution selection scheme which select the optimal MV resolution in a scientifically sound way with rate-distortion optimization. Specifically, the prediction distortion and rate models in terms of the MV resolution are established by taking the local properties of the input sequence into account. Based on our method, more flexibilities could be provided to achieve the MV resolution adjustment on frame and block and improve coding efficiency significantly.
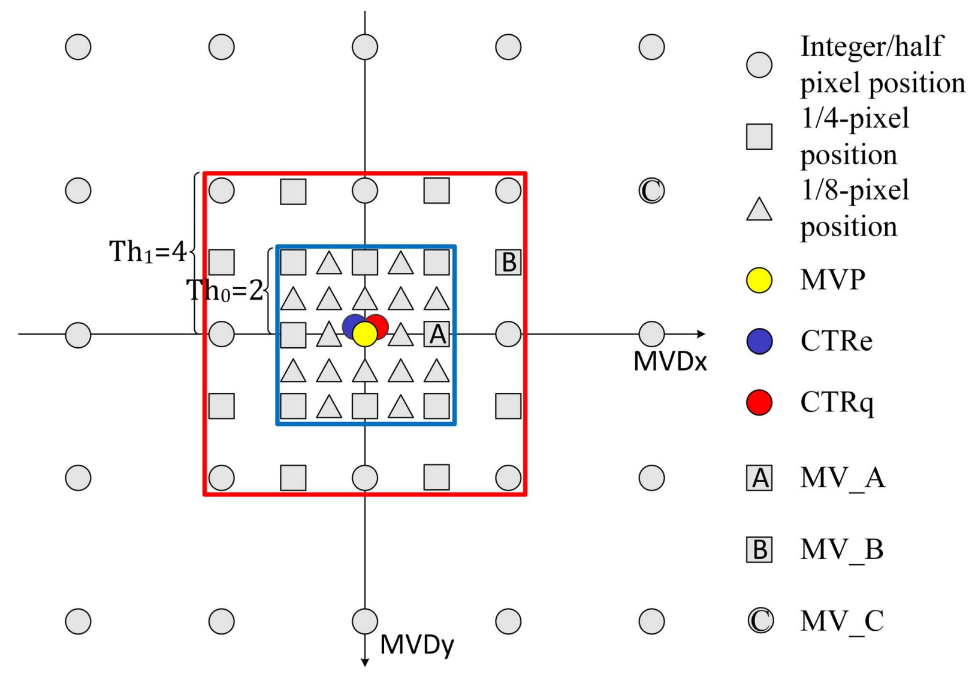
Illustration of the PMVR
Three-Zone Segmentation Based Motion Compensation
Motion compensation (MC) has been widely employed for removing temporal redundancies in typical hybrid video coding framework. To improve the performance of MC, a frame is usually divided into non-overlapped sub-regions as the basis to capture motion characteristics. However, block based MC may not align with the actual object motion boundaries, potentially limiting the compression efficiency. In view of this, we propose a three-zone segmentation based motion compensation scheme to improve the description accuracy of motion field as well as the coding efficiency. In particular, image segmentation is applied on the reference block to locate the object edges, and then the reference block is divided into three zones, including one foreground zone, one background zone and one edge zone. The background zone will obtain refined MV based on the local motion field, the prediction of the foreground zone is improved by the multi-hypothesis prediction and the edge zone is processed as an overlapped zone and the weighted compensated strategy is adopted in edge zone.
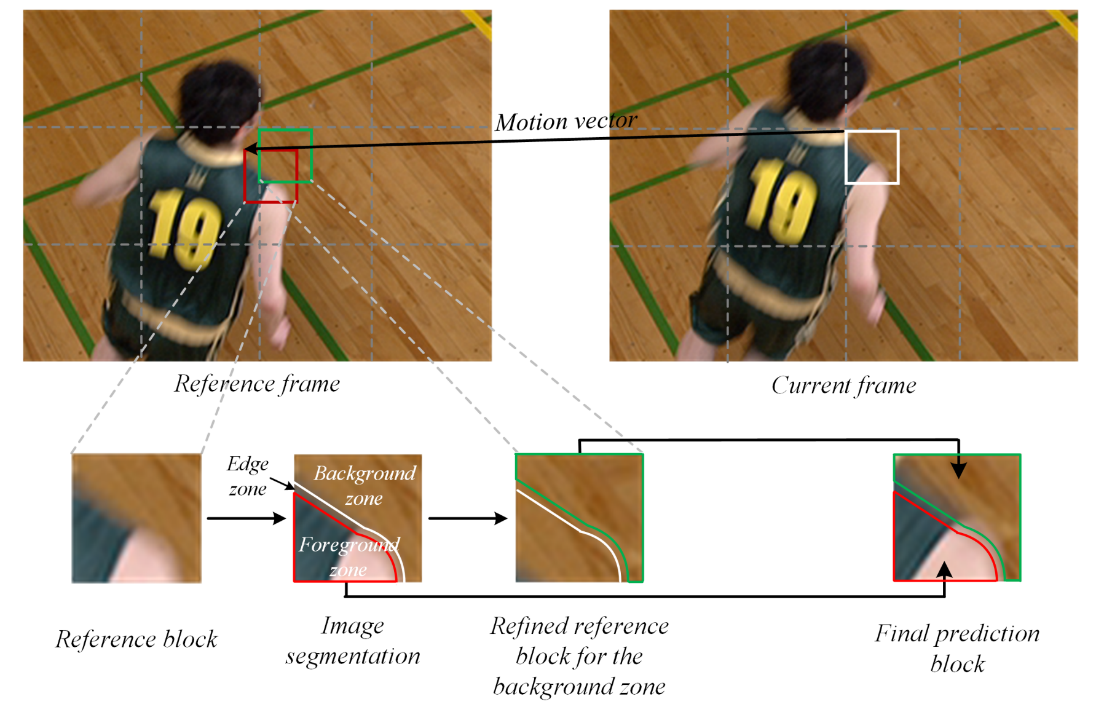
Illustration of three-zone segmentation based motion compensation scheme
Hybrid All Zero Soft Quantized Block Detection
There are a large number of discrete cosine transform coefficients which are finally quantized into zeros. In essence, blocks with all zero quantized coefficients do not transmit any information, but still occupy substantial unnecessary computational resources. As such, detecting all-zero block (AZB) before transform and quantization has been recognized to be an efficient approach to speed up the encoding process. We incorporate the properties of soft-decision quantization into the AZB detection, instead of considering the hard-decision quantization (HDQ) only. In particular, we categorize the AZB blocks into genuine AZBs (G-AZB) and pseudo AZBs (P-AZBs) to distinguish their origins. For G-AZBs directly generated from HDQ, the sum of absolute transformed difference-based approach is adopted for early termination. Regarding the classification of P-AZBs which are generated in the sense of rate-distortion optimization, the rate-distortion models established based on transform coefficients together with the adaptive searching of the maximum transform coefficient are jointly employed for the discrimination.

The workflow of G-AZB and P-AZB detection.
Hybrid Laplace Distribution-Based Low Complexity Rate-Distortion Optimized Quantization
Rate distortion optimized quantization (RDOQ) is an efficient encoder optimization method that plays an important role in improving the rate-distortion (RD) performance of the high-efficiency video coding (HEVC) codecs. However, the superior performance of RDOQ is achieved at the expense of high computational complexity cost in two stages RD minimization. To reduce the computational cost of the RDOQ algorithm in HEVC, we propose a low-complexity RDOQ scheme by modeling the statistics of the transform coefficients with hybrid Laplace distribution. In this manner, specifically designed block level rate and distortion models are established based on the coefficient distribution. Therefore, the optimal quantization levels can be directly determined by optimizing the RD performance of the whole block, while the complicated RD cost calculations can be eventually avoided.
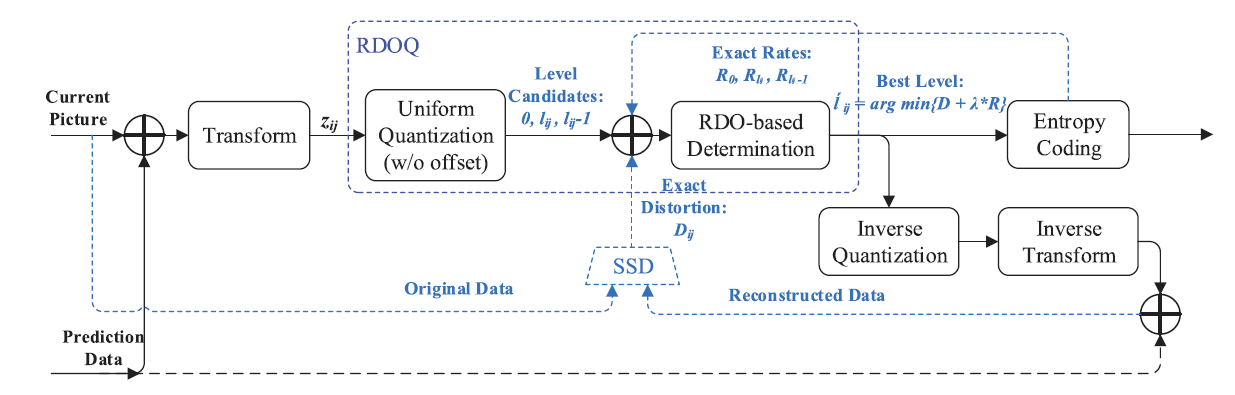
The proposed exact cost RDOQ scheme for model parameters training.
Non-local Structure-based in-loop filter (NLSF)
The existing in-loop filters in video coding standard, i.e. Deblocking Filter, Sample Adaptive Offset and Adaptive Loop Filter, are only based on local correlation without fully exploiting nonlocal similarity structure in video. In view of this, we propose non-local structure-based in-loop filter (NLSF) by simultaneously enforcing the intrinsic local sparsity and the non-local self-similarity of each frame. NLSF not only deals with the boundary pixels, but also the inside area, which is able to effectively reduce block artifacts while enhancing the quality of the deblocked frames.
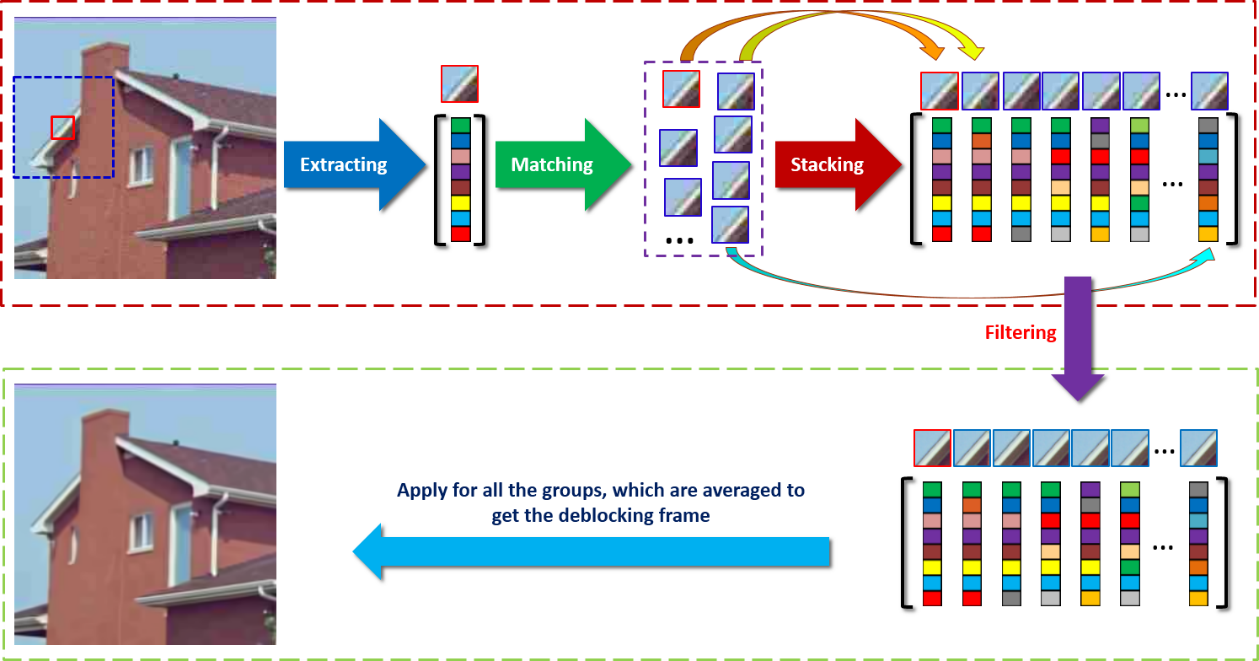
Illustrations for NLSF
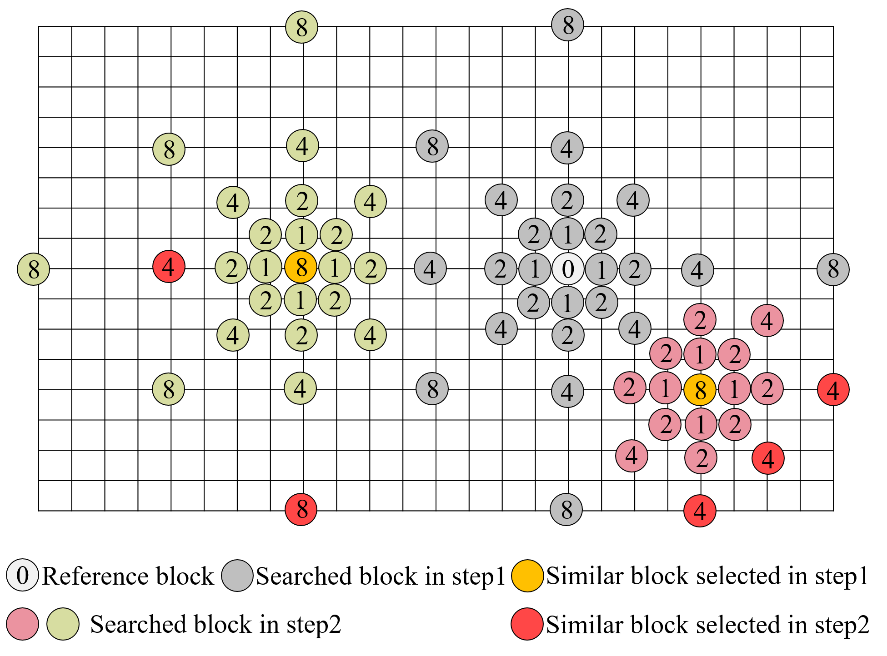
Fast block matching algorithm for NLSF
2. Versatile Video Coding (VVC)
To further improve coding efficiency, the Joint Video Exploration Team (JVET) begins to develop the next generation video coding standard, Versatile Video Coding (VVC), in October 2017. VVC, which is a block-based hybrid video coding standard, is still in development and we have many proposals adopted by it.
Hardware-friendly Inter/Intra Coding Scheme in VVC
Compared to HEVC, there are many new inter/intra prediction technologies adopted in VVC, such as History-based MVP (HMVP), shared merge list, triangle prediction, Sub-block TMVP (SbTMVP), Cross-Component Linear Model prediction (CCLM) and so on. Those newly adopted tools may cause higher storage burden or longer pipeline latency and we propose optimization scheme to improve the hardware friendliness of them.
Storage reduction and simplification
In shared merge list, there are two HMVP tables maintained for coding small blocks in VVC. We propose to use a single HMVP table, which can reduce the storage burden of HMVP in shared merge list by half.
In triangle prediction, a CU is split evenly into two triangle-shaped partitions, using either the diagonal split or the anti-diagonal split. After predicting each triangle partition using its own motion, blending is applied to the two prediction signals to derive samples around the diagonal or anti-diagonal edge. As the derivation of bi-prediction MV to be stored in the blending area is complicated. We propose to remove the reference picture mapping process and store uni-prediction MV in the area when MV1 and MV2 are from the same reference list.
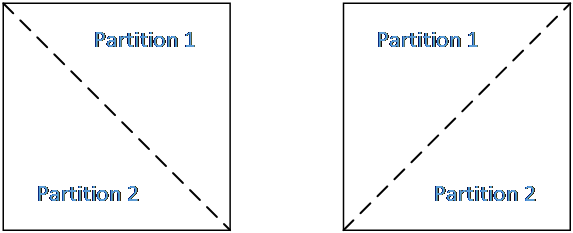
Triangle partition based inter prediction
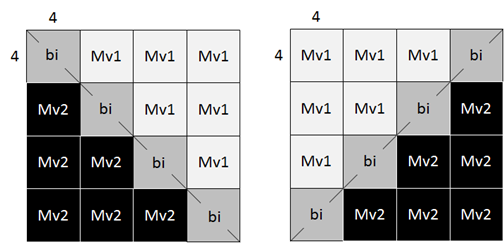
An example of motion vector storage for triangle prediction
Latency reduction
SbTMVP derives multiple motion for sub-blocks of one coding unit (CU) based on the motion information of the collocated blocks from temporal reference picture. Although it has improved the coding efficiency of inter prediction, complexity issues still exist. We proposed:
- a) Restricts the number of scanning process for deriving the collocated block to one time and therefore both the average and worst-case complexity is reduced.
- b) Fix the sub-CU size of SbTMVP to 8x8
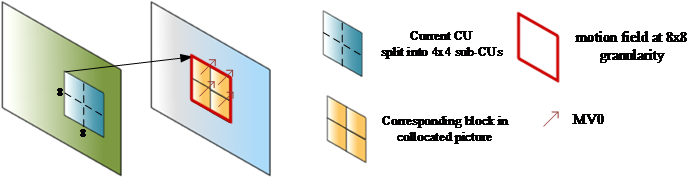
Illustration of SbMVP
Because of the adoption of SbTMVP, there are some unnecessary Temporal Motion Vector Prediction (TMVP) in inter prediction. In order to reduce the timing of small blocks, we propose to remove TMVP from merge list and AMVP list at specified small block sizes.
CCLM is to reduce the cross-component redundancy, for which the chroma samples are predicted based on the reconstructed luma samples by using a linear model. The dependency of the parsing process of chroma prediction mode causes latency for hardware design. We propose a hardware-friendly scheme to remove the context selection dependency.
Context selection for bins related to intra chroma mode coding(CCLM on)

High Level Syntax Design for Adaptive Loop Filter in VVC
Adaptive Loop Filter (ALF) is adopted to VVC to minimize the mean square error between original and reconstructed samples by using Wiener-based filter. ALF can improve coding efficiency significantly. However, the coefficients and parameters of ALF may cause huge overhead. Hence, high level syntax design is important to reduce the overhead caused by ALF. We propose to redesign the ALF clipping parameter coding method by using fixed length coding and remove the dependency between ALF coefficients to reduce overhead while simplify encoder and decoder complexity.
Filter shape of adaptive loop filter
Probabilistic Decision Based Block Partitioning
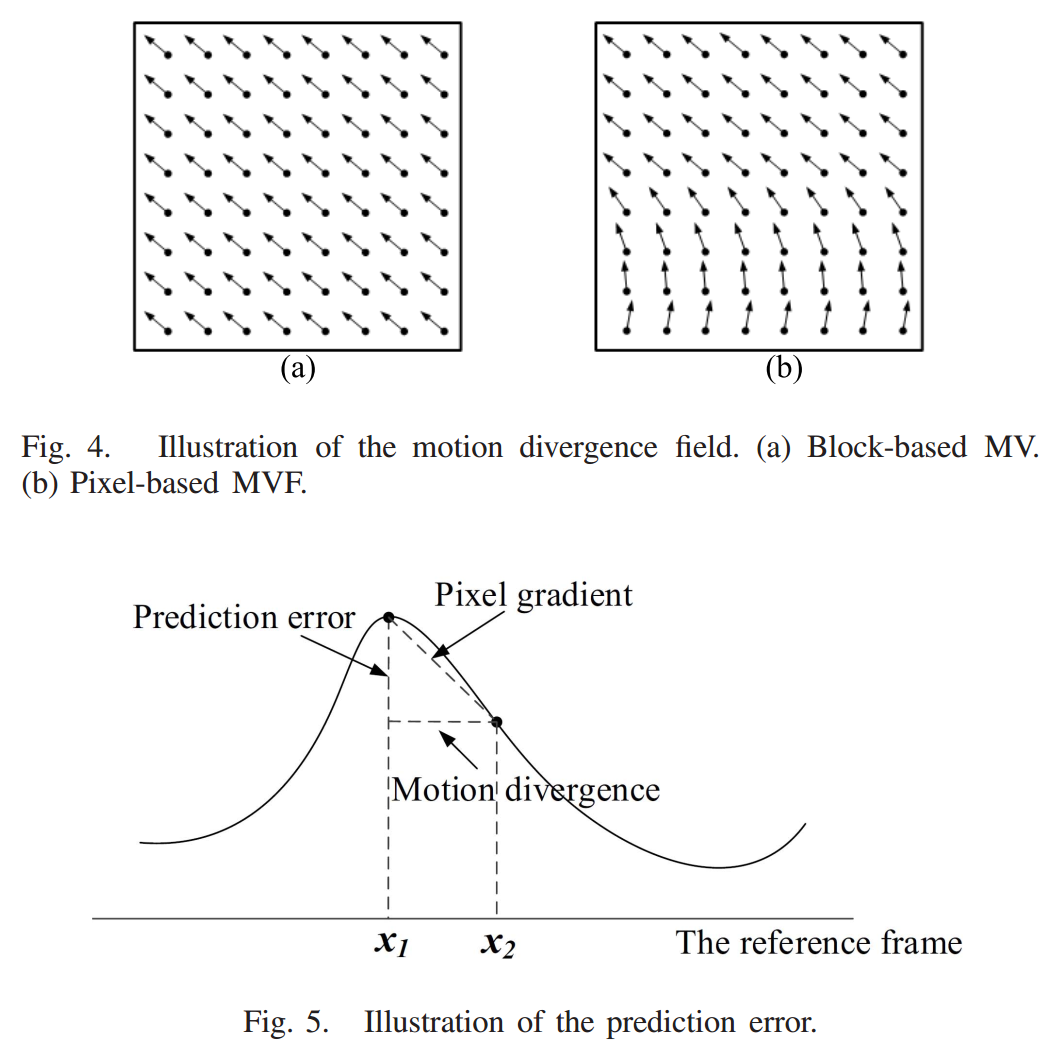
During the development of VVC, the quadtree plus binary tree (QTBT) block partitioning structure was proposed. Compared to the traditional quadtree structure of High Efficiency Video Coding (HEVC) standard, QTBT provides more flexible patterns for splitting the blocks, which could improve the coding performance dramatically but result in high computational complexity. We propose a confidence interval based early termination scheme for the QTBT block partitioning structure to identify the unnecessary partition modes in the sense of rate-distortion (RD) optimization. In particular, a RD model based on motion divergence field is established to predict the RD cost of each partition mode without the full encoding process. To further improve the partition accuracy and achieve a good trade-off between the coding performance and the computational complexity, we cast the mode decision problem into a probabilistic framework which could be regarded as a binary-classification problem to eliminate unnecessary partition iterations.
3. Audio Video Coding (AVS3)
Initiated by AVS Working Group of China, AVS has become an international standard family for digital audio/video compression and transmission, endorsed by IEEE. AVS-3 is an emerging next-generation video coding standard beyond AVS-2. In the first phase of AVS-3 standardization, numerous efficient tools have been studied and adopted, and the coding performance increases about 20% compared to AVS2, meanwhile, the decoding time decreases substantially. especially for 4K sequences, the coding performance increases nearly 30% compared to HEVC. In one and a half year time, the Profile2 and Profile3 of AVS3 will be drafted, which aims to save the coding bit-rate more than 40% and 60% respectively.
Intelligence Video Coding
In recent years, the image and video coding technologies have advanced by leaps and bounds. However, due to the popularization of image and video acquisition devices, the growth rate of image and video data is far beyond the improvement of the compression ratio. With the development of deep learning, we also try to use deep learning to boost video coding. Deep convolution neural network (CNN) which makes the neural network resurge in recent years and has achieved great success in both artificial intelligent and signal processing fields, also provides a novel and promising solution for image and video compression. More specifically, the cutting-edge video coding techniques by leveraging deep learning and HEVC framework are investigated and discussed, which promote the state-of-the-art video coding performance substantially.
CNN-Based Bi-Directional Motion Compensation for HEVC
The state-of-the-art High Efficiency Video Coding (HEVC) standard adopts bi-prediction to improve the coding efficiency for B frame. However, the underlying assumption of this technique is that the motion field is characterized by the block-wise translational motion model, which may not be efficient in the challenging scenarios such as rotation and deformation. Inspired by the excellent signal level prediction capability of deep learning, we propose a bi-directional motion compensation algorithm with convolutional neural network, which is further incorporated into the video coding pipeline to improve the performance of video compression.
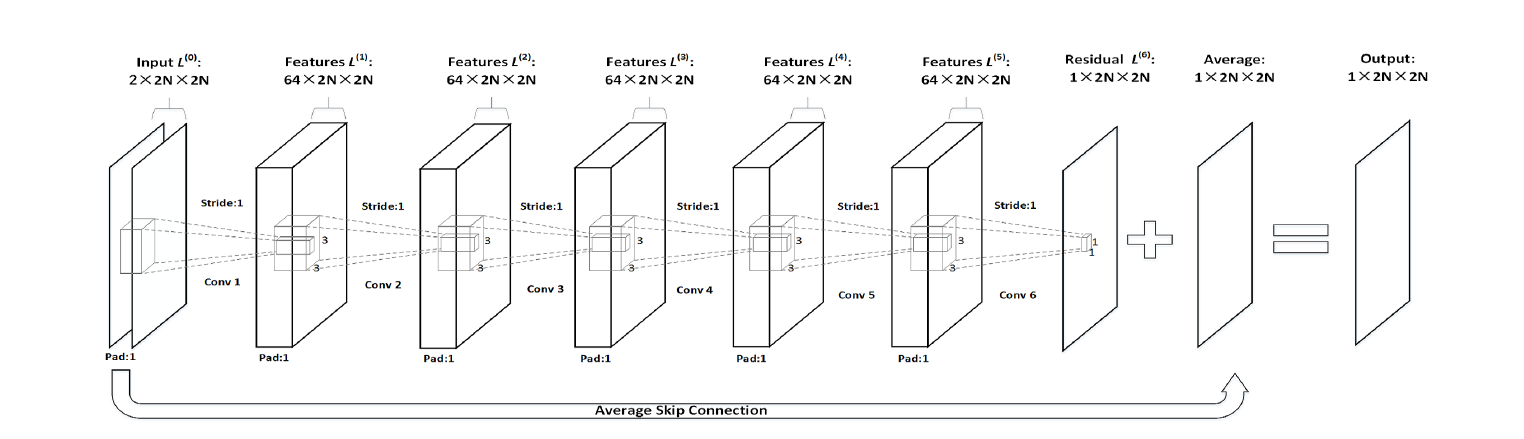
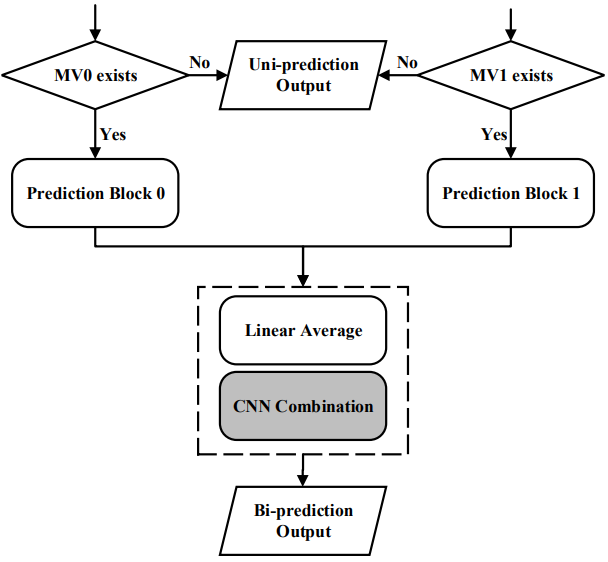
Figure 1 Top: The network architecture; bottom: the flowchart of CNN based bi-directional inter prediction in video coding
Content-Aware Convolutional Neural Network for In-loop Filtering in High Efficiency Video Coding
Recently, convolutional neural network (CNN) has attracted tremendous attention and achieved great success in many image processing tasks. We focus on CNN technology joining with image restoration to facilitate coding performance, and propose the content-aware CNN based in-loop filtering for High Efficiency Video Coding (HEVC). More specifically, each Coding Tree Unit (CTU) is treated as an independent region for processing, such that the proposed content-aware multi-model filtering mechanism is realized by the restoration of different regions with different CNN models under the guidance of the discriminative network. To adapt the image content, the discriminative neural network is learned to analyze the content characteristics of each region for the adaptive selection of the deep learning model.
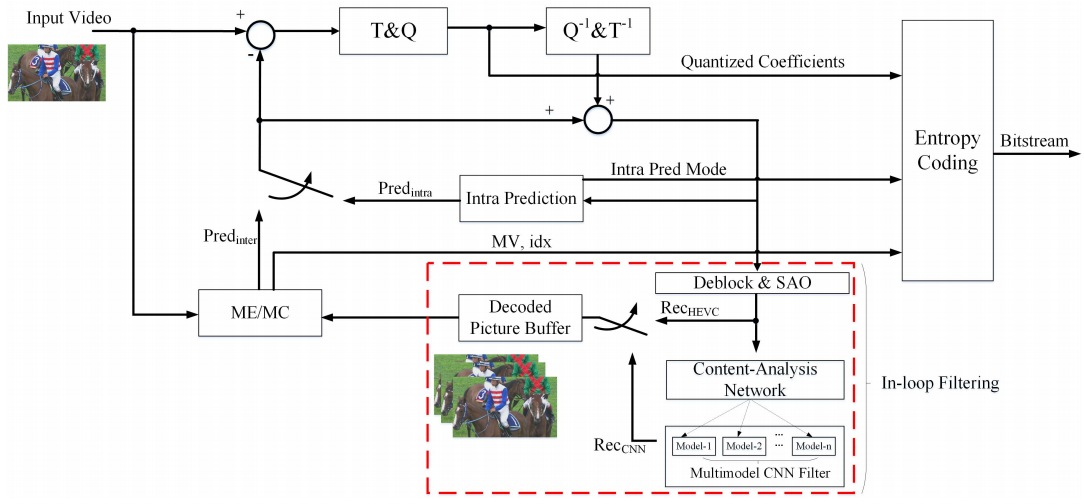

Figure 2 Left: Content-aware CNN in-loop filter for HEVC right: R-D curves
Enhance CTU-Level Inter Prediction with Deep Frame-Rate Up-Conversion for HEVC
The state-of-the-art video coding standard employs the reconstructed frames as the references in the process of inter prediction. Motion vector conveys the relative position shift between the current block and the prediction block, and it is explicitly signaled into the bitstream. We propose a high efficient inter prediction scheme by introducing a new virtual reference framework. In particular, the high quality virtual reference frame is generated with the deep learning based frame rate up-conversion (FRUC) algorithm from two reconstructed bi-prediction frames

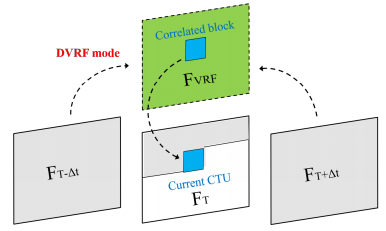
Figure 3 The Frame-rate-up-conversion based inter prediction using Deep Virtual Reference Frame (DVRF) generation
CNN-based fast QTBT partitioning decision
Recently, the convolution neural network (CNN) has been found to be an effective method in determining the behavior of codec. We design a single network to predict the depth range of QTBT partitioning for 64x64 Coding Unit (CU). Firstly, we apply motion compensation to the original block and convert it into residual block. Then, the residual block is subtracted by the mean intensity values. After pre-processing, 4x4 kernels at the first convolutional layer is used to extract the low level features. For the second and third layers, feature maps are further convoluted twice with 2x2 kernels. The final feature map is concatenated together and flatten into a vector. In the proposed method, the QTBT partitioning decision is modelled as a multi-classification problem and the false prediction risk is controlled based on temporal correlation to improve the robustness of the scheme.
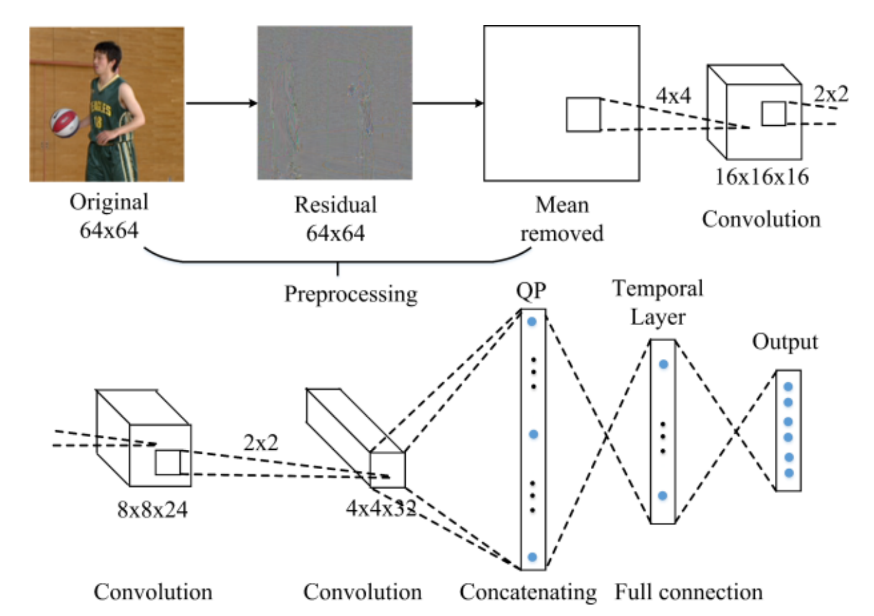
Architecture of the CNN for QTBT fast partitioning
Image/Video Processing and Quality Assessment
1. Enhanced Image Decoding
With the explosion of digital media services, there is an increasing demand to compress the images/videos to facilitate storage and transmission, which may degenerate their quality especially at low bit rate. The popular lossy compression standards (e.g., JPEG and HEVC) adopt the block-based compression architecture and quantize every block independently to reduce the amount of transform coefficients. Lossy image compression usually introduces undesired compression artifacts, such as blocking, ringing and blurry effects, especially in low bit rate coding scenarios. Although many algorithms have been proposed to reduce these compression artifacts, most of them are based on image local smoothness prior, which usually leads to over-smoothing around the areas with distinct structures, e.g., edges and textures, leading to poor user experience.
Perceptual-oriented Enhanced Image Decoding
To reconstruct a high quality decoded image, we incorporate the latest generative adversarial networks (GANs) to predict visually pleasing texture. Besides, the edge prior of original images has also been exploit for preserving edge fidelity. We proposed edge-preserving generative adversarial network (EP-GAN) to achieve edge restoration and texture generation simultaneously, resulting in high-quality perceptual results.
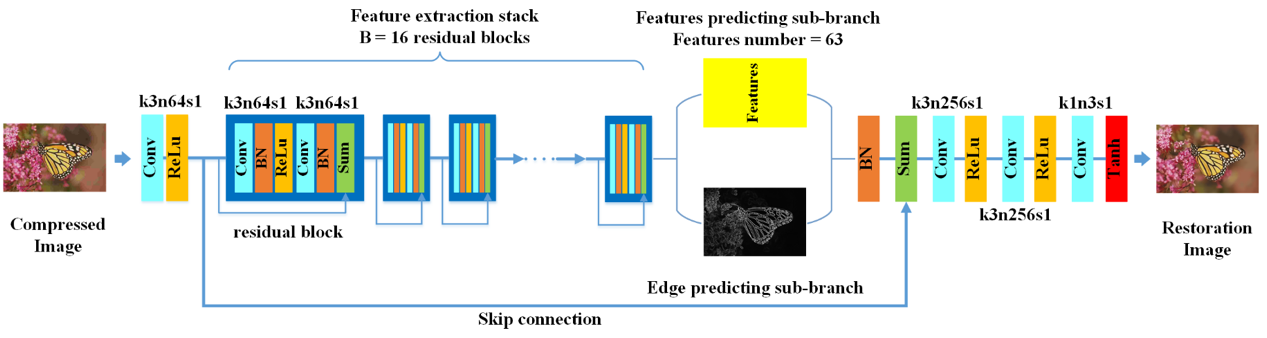
Figure 1 Edge-preserving Generative adversarial network (EP-GAN)

Figure 2 Comparisons with state-of-the-art method ARCNN
Balance Fidelity and Quality via Hybrid Framework
However, GANs always lead to poor objective results such as PSNR, which means low fidelity. Therefore, we further introduce a region-aware visual signal restoration scheme to achieve a good balance between visual quality and fidelity with hybrid neural networks, such that the base fidelity layer and texture quality enhancement layer are combined adaptively to restore the compressed images.
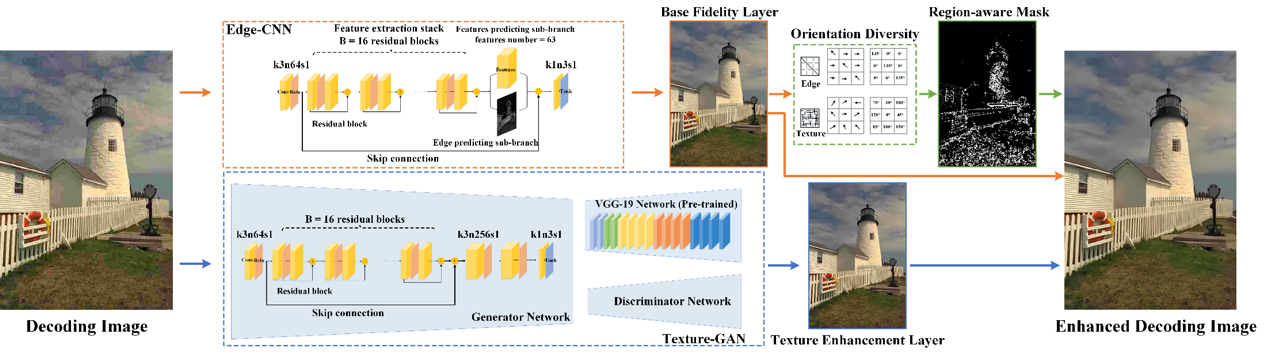
Figure 3 The framework of region-aware enhanced image decoding.
2. Image Quality Assessment
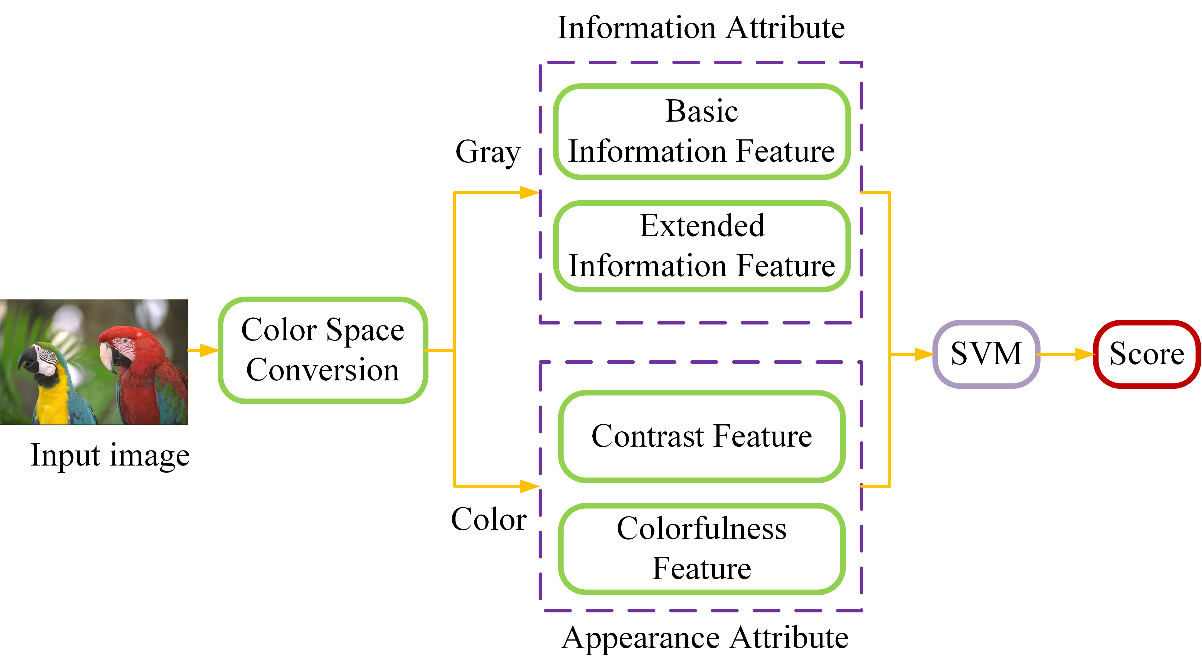
Contrast distortion has a significant influence on the perceptual quality of an image, which may be generated in various image processing procedures. We propose a no-reference image quality assessment (IQA) algorithm for contrast-distorted images based on hybrid features from information and appearance attributes. From information attribute aspect, we utilize the basic information feature to quantify the information of the visible part and the extended information feature further containing the invisible part of an image. From the appearance aspect, we propose an efficient perceptual contrast and colorfulness index to capture the direct visual changes. With the hybrid information attribute and appearance attribute features, support vector regression (SVR) is utilized to learn an IQA model to predict the quality of contrast distorted images. Extensive experimental results on CCID2014 and TID2013 databases further demonstrate the superior performance and robustness of the proposed method.
Cross-Media Application
We also aim to study the problem of better retaining the semantic information when transforming across different media formats, such as videos, images, texts, and audios. Concretely, we have conducted research in various cross-media analysis and generation tasks, including image/video captioning, audio/text based image generation, pose-guided human action video generation, etc.
Pose-guided Human Action Video Generation
Human action video generation has attracted increasing attention due to its great potential in many application scenarios, such as creative movie making, interactive fashion design, and dataset augmentation for video analysis tasks. We propose a two-stage decoupled learning framework for generating human action videos with both visual and motion conditions, where the attribute encoder and pose-aware generator are separately trained over color-augmented video frames to achieve better feature disentanglement. Compare to existing end-to-end learning schemes, our framework can produce more diverse human action videos where the color of clothes can be flexibly manipulated through latent codes.
Figure 1 Framework

Figure 2 Generated human action videos
Self-critical n-step Training for Image Captioning
Image captioning aims at generating natural captions automatically for images. Recently it has been shown advantages of incorporating techniques from reinforcement learning into training, where one of the popular techniques is the advantage actor-critic algorithm that calculates per-token advantage by estimating state value with a parametrized estimator at the cost of introducing estimation bias. Here, we estimate per-token advantage without using a parametrized value estimator. With the properties of image captioning, we reformulate advantage function by simply replacing the state value with its preceding state-action value. Moreover, the reformulated advantage is extended to n-step, which can generally increase the absolute value of reformulated advantage. Then two kinds of rollout are adopted to estimate state-action value, which we call self-critical n-step training. Empirically we find that our method can obtain better performance compared to the state-of-the-art methods that use the sequence level advantage and parametrized estimator respectively.
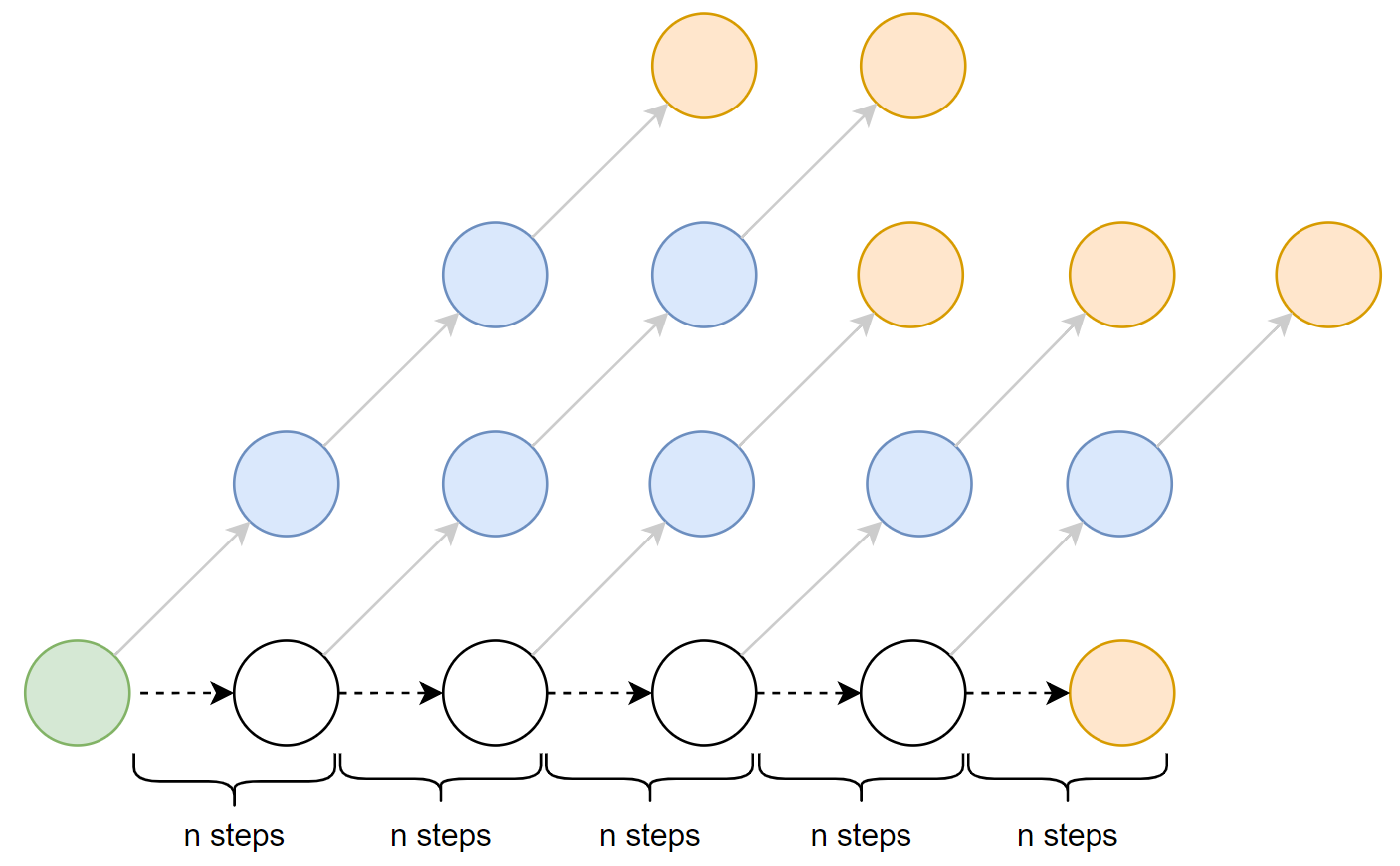
Figure 3 n-step training for image caption
System Development
We also transfer algorithms into actual engineering projects, including 863 project, number of projects cooperated with many enterprises.
Codec system optimization
Interpolation is a very important module in inter prediction for any video decoder, e.g. AVS2 and HEVC, which occupies most of the time in the whole decoding process. Thus, the real-time decoder is largely limited by the speed of inter prediction. To solve this problem, we propose an efficient GPU-based interpolation framework for inter prediction. Through optimizing shared memory allocation and thread scheduling on the GPU side, GPU are utilized efficiently and inter prediction is accelerated effectively. The experimental results on AVS2 show that for all Ultra HD 4K, WQXGA and full HD video sequences tested, the inter prediction acceleration ratio is over 6 times, and the average processing time is up to 1.25ms, 0.75ms and 0.45ms, respectively, with the NVIDIA GeForce GTX 1080TI GPU.
Point cloud compression system
We propose a novel point cloud compression method for attributes, based on geometric clustering and Normal Weighted Graph Fourier Transform (NWGFT). Firstly, we divide the entire point cloud into different sub-clouds via K-means based on the geometry to acquire sub-clouds with more uniform structures, which enables efficient representation with less cost. Secondly, for the purpose of reducing the redundancy further, we apply NWGFT to each sub-cloud, in which graph edge weights are derived from the similarity in normal combining the local and global features of point clouds.
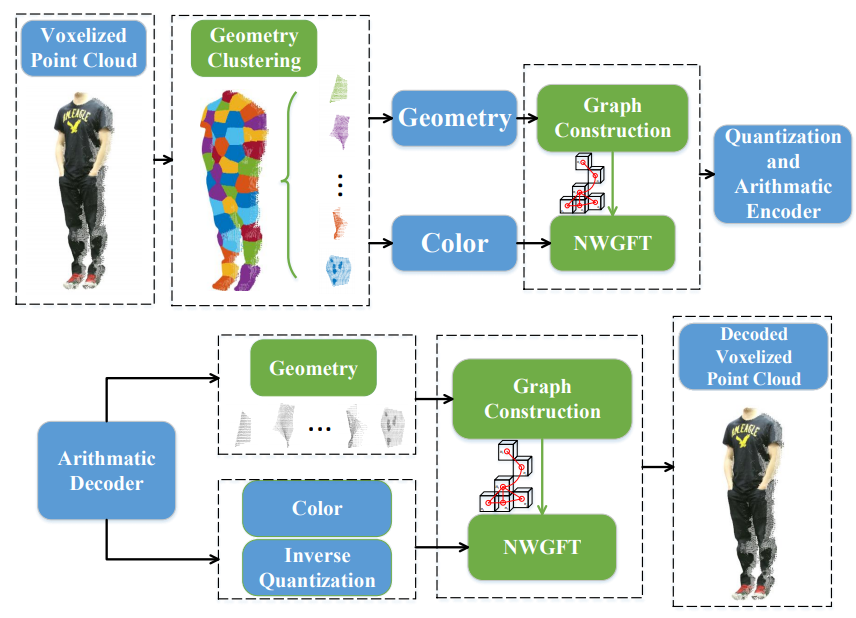
We propose an adaptive scanning scheme to improve color attribute compression performance of static point cloud. To better exploit the intrinsic correlations of point cloud color data, multiple scanning modes are dedicated to projecting the color attributes into a series of texture blocks before compression. The best mode is subsequently selected in the sense of rate distortion optimization, such that the compression flexibility and performance can be greatly improved. To achieve rate-distortion optimized scan, the Lagrange multiplier that balances the rate and distortion is off-line derived based on the statistics of color attribute coding.
VAMR (Virtual, Argument, Mixed Reality) System
VAMR system focuses on the research about XR and related systems. The VR systems we developed have been invited to participate China International Industry Fair.
Wandering in Yanyuan System:
Cave System