2018年7月10日至15日,国际机器学习顶级学术会议 ICML (International Conference on Machine Learning) 在瑞典首都斯德哥尔摩举行,参会人数创历史新高,达到了5000人。会议共收到2473篇投稿,录取621篇,录稿率约25%。论文单位中包含北京大学的(含第一单位)共有10篇,其中,北京大学数字视频编解码技术国家工程实验室教授、前沿计算研究中心副主任王亦洲老师课题组共有2篇论文被录用。

第一篇论文:MSplit LBI: Realizing Feature Selection and Dense Estimation Simultaneously in Few-shot and Zero-shot Learning
下载: https://arxiv.org/pdf/1806.04360.pdf
在很多分类或者回归任务中,需要学习一个线性映射。传统方法通常使用 L1 和 L2 正则项来约束模型。然而,L1 正则项存在两个主要问题:1)在不可表示条件不成立时,会造成强信号的不准确估计;2)由于对弱信号的忽略,会造成对训练数据集欠拟合。此外, L2 正则项无法实现特征选择,同时会造成有偏估计。
 为了克服上述 L1 和 L2 正则项的问题,这篇文章提出 MSplit LBI 将特征分解成强信号,弱信号和随机噪声。模型得到的强信号可用于特征选择,弱信号可以用于结合强信号进一步提高拟合的精确度。文章设计如下的正则项:
为了克服上述 L1 和 L2 正则项的问题,这篇文章提出 MSplit LBI 将特征分解成强信号,弱信号和随机噪声。模型得到的强信号可用于特征选择,弱信号可以用于结合强信号进一步提高拟合的精确度。文章设计如下的正则项:
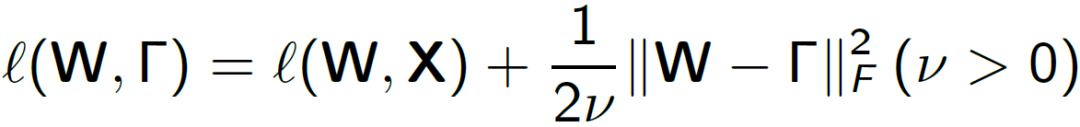
式中 X 表示输入, W 表示线性映射矩阵。引入了稀疏项 Γ 来逼近非稀疏项 W。Msplit LBI 采用梯度下降来求解,求解算法如下:
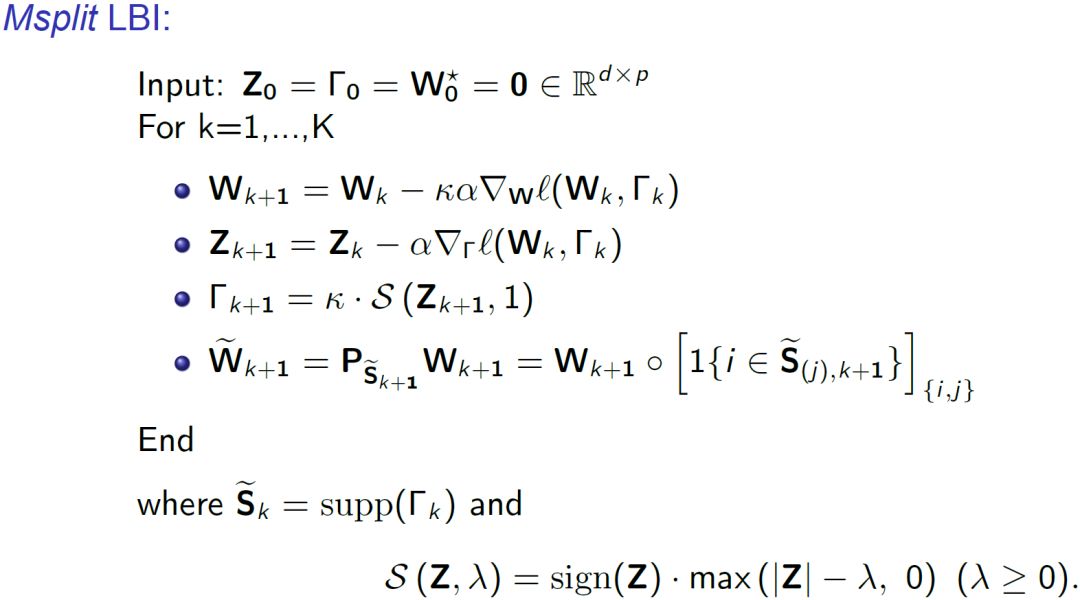
作者分别在模拟数据和真实数据(few-shot learning 和 zero-shot learning)上对模型进行了测试,并对比了 baseline (L1, L2) 和 state-of-the-art 方法。下表中的实验结果展示了 Msplit LBI 在 zero-shot learning 问题上取得了超越 state-of-the-art 的识别准确率。

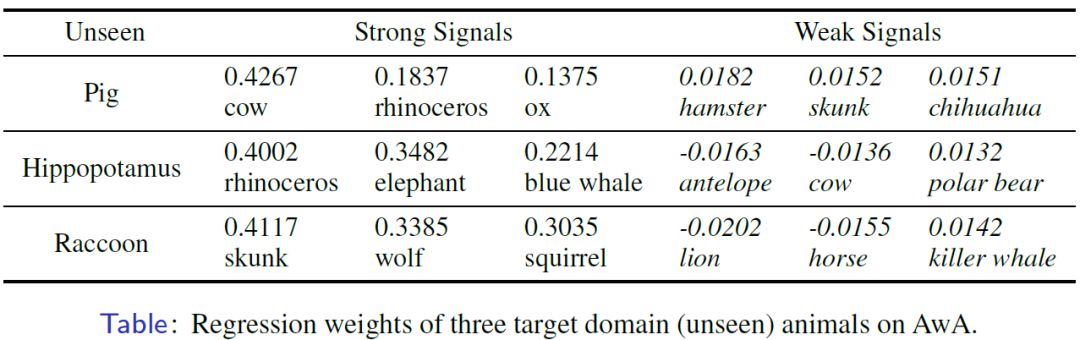
在 zero-shot learning 实验中,需要用已知类(seen classes)的数据对未知类(unseen classes)数据进行拟合。下表展示的是对三种已知动物(pig, hippopotamus, raccoon)的拟合参数。可以发现 Msplit LBI 计算得到的强信号和弱信号都十分合理,具有很好的可解释性。
更多算法细节、理论证明和实验结果请参考原文。
第二篇论文:End-to-end Active Object Tracking via Reinforcement Learning
下载: https://arxiv.org/abs/1705.10561
对于移动机器人和无人机等视角会变动的平台或目标会离开当前拍摄场景的情况,跟踪目标时通常还需要对摄像头的拍摄角度进行持续调整。这种通过主动调节摄像头从而保证目标出现在画面中合理位置的任务,我们称之为主动目标跟踪。该论文提出了一种使用强化学习的端到端的主动目标跟踪方法,可直接根据画面情况实时调整摄像头的运动。具体而言,研究者使用了一个 ConvNet-LSTM 网络,其输入为原始视频帧,输出为相机运动动作(前进、向左等)。而传统的实现上述任务的方法,需要先训练一个被动跟踪器,提取出目标在画面中的位置,再利用位置信息调节相机控制器。

上图展示了研究者提出的端到端主动跟踪方法与传统方法的差别。传统方法需要分步调参,实现较为复杂。

上图展示了这个 ConvNet-LSTM 网络的架构,其中的强化学习部分使用了一种当前最佳的强化学习算法 A3C。
因为在现实场景上训练端到端的主动跟踪器成本代价较高,所以研究者在 ViZDoom 和 Unreal Engine 两个虚拟环境中进行了训练。在这些虚拟环境中,智能体(跟踪器)以第一人称视角观察状态(视觉帧)并采取动作,然后环境会返回更新后的状态(下一帧)。为了引导智能体更好更快得学习,研究者还设计了一个新的奖励函数以让智能体更加紧跟目标。
实验结果表明,这种端到端的主动跟踪方法能取得优异的表现,并且还具有很好的泛化能力,能够在目标运动路径、目标外观、背景不同以及出现干扰目标时依然稳健地执行主动跟踪。另外,当目标偶尔脱离跟踪时(比如目标突然移动),该方法还能恢复对目标的跟踪。下表给出了不同跟踪方法在 ViZDoom 环境的几个不同场景上的表现比较,其中 AR 表示累积奖励(类似于精确度),EL 表示 episode 长度(类似于成功跟踪的持续帧数)。

最后,作者还在 VOT 数据集上执行了一些定性评估,来探究用虚拟场景训练的的跟踪器是否有可能直接迁移到真实世界场景当中应用。

上图展示的是给我们跟踪器输入一个视频序列时,对应输出的动作与目标之间关系。横坐标代表目标中心与图像中心之间的偏离量,纵坐标代表目标的大小,红点代表右转动作,绿点代表左转动作,黄点代表停止。由此可见,我们用纯虚拟环境数据训练的端到端主动跟踪器是有可能迁移到真实世界场景中应用的。
更多细节和实验结果请参考原文。
